A MINERAL EXPLORATION COMPANY · CENTRAL ASIA · SOVIET-ERA ARCHIVE DIGITISATION
| 99%+ | structured extraction accuracy, against 3–5% from the prior OCR process |
| ~3M | pages across ~15,000 report bundles (3.5TB) processed end-to-end |
| 900k+ | structured grade records extracted across five commodities |
The Challenge
A mineral exploration company held one of the richest untapped geological archives in Central Asia — perhaps the world: around 15,000 report bundles, 3.5–4 million pages, 3.5TB of Soviet-era exploration intelligence. Drill logs, geological maps, field notes — almost entirely in Russian Cyrillic, much of it handwritten, stamped or degraded.
Almost none of it was searchable. The company's prior in-house OCR process returned 3–5% usable extraction. The value sat locked inside the paper.
And this was not clean text. The corpus contained an extensive list of Soviet-era drill-hole passports — the Паспорт скважины family, single images carrying up to ~20,000 data points each — alongside multi-hole stratigraphic correlation panels with two to nine boreholes on one sheet, and analogue geological maps that mean nothing until they are georeferenced. The manual route to unlock it ran to 18–24 months of full-time work and a team of specialist hires, with no guarantee of a top-tier technical outcome.
The bottleneck was never access to the data. It was the human capacity to read, validate and structure it at scale.
What Pulse Did
Pulse delivered a modular, AI-native pipeline — not a one-off OCR job, but a system. Phase 1 ran high-accuracy OCR and bilingual extraction (original Russian and English) across all ~15,000 bundles, layout and tables preserved. An early engineering breakthrough — resolving a memory leak and introducing LLM batching — cut a full-corpus run from 32 hours to five.
On top of the text, Pulse built the structure. AI metadata extraction classified every document across 13 types. A 100-element normalisation table reconciled Russian, Latin, chemical-symbol and Soviet-specific terminology. A 19-field drill-hole schema captured everything from coordinates and depth intervals to lithology, age and multi-element assays — with original and normalised units retained, outliers flagged and sample type tagged.
The Complexity, Solved
The hard parts are the point. Pulse's hybrid stack — computer vision, Tesseract, LLM extraction and statistical reconciliation — extracts the Soviet drill-hole passports at ground-truth-validated accuracy, and digitises the multi-hole correlation panels down to a per-hole table.
Geological maps and analogue records are georeferenced at 1:200k and 1:50k scale. And the Coordinate Reference System is captured natively at ingest — closing the silent failure that plots a drill hole hundreds of kilometres off-truth because the CRS was dropped along the way. Errors are made to look like errors: a hole that lands 200km from its neighbours is caught on sight.
What It Changes for a Geologist
For the people using it, the shift is concrete. Instead of scrolling thousand-page reports to find one number, a geologist asks a question in plain language — and the platform answers in both Russian and English, with the interface itself running in either language — returning the figure with a link to the exact source page. Every historical grade and interval tied to a target is surfaced and reconciled in seconds, not an afternoon of manual reading.
Named occurrences come back as pre-digested summaries — location, mineralisation, grade context — drawn from every report that ever mentioned them, and plotted on a map. The work that used to mean a printout, a ruler and half a day becomes a query. That is the outcome the team actually cares about: more targets reviewed, faster, with the evidence attached and traceable.
The Outcome
Structured accuracy of 99%+ replaced the 3–5% the company started with. Around 900,000 grade records were extracted across the full corpus. Against the original proposal, thirteen contracted deliverables were completed in full, and nine further capabilities — the MCP server, occurrence intelligence, image-attachment OCR, the ring-fenced data room for a joint-venture partner — were delivered above and beyond scope.
From Archive to Infrastructure
The more important shift is what the archive became. It is no longer a digitisation project — it is the company's live data infrastructure, running inside a dedicated, client-encrypted environment. It now ingests on two fronts at once: the company's own newly acquired documents, and the public-market flow — disclosures, filings and drill results from 17 exchanges — pulled in automatically and continuously. New data lands and runs end-to-end through the same pipeline, with no manual intervention.
The team queries the entire corpus in natural language through the Pulse Claude MCP, from inside their own AI workflows — every answer linked back to its source document and page. Translated reports, occurrences and drill collars surface as a Pulse-served spatial layer inside their existing ArcGIS Pro environment, with no change of tooling. And a two-schema validation model — raw data in a holding schema, promoted to a master schema by the people who know the rocks — builds a clean, audit-traceable dataset that compounds over time.
A dormant archive became the operating system beneath the team's exploration, targeting and deal-evaluation work — at less than a third of the cost and time of the manual route, with no new internal hires. As the team framed their own core test: find 50 metres at 0.5% copper buried in the archive, and material value falls straight out of the screen.
Ready for Diligence — and the Next Deal
The same engine is now on call for whatever data comes next. When the team runs diligence on an acquisition target, opens a new data room, or brings in a freshly acquired dataset, those documents flow into the same pipeline and come back structured, validated and queryable almost immediately — no new project, no wait.
For a corporate-development team, the payoff is speed and certainty: a fast, evidence-backed read on what a deal actually contains, the moment the data lands. Every future diligence process or acquisition compounds onto the same foundation rather than starting from scratch.
Further reading: The discipline behind this work — why mining-grade data normalisation is the most underestimated bottleneck in the industry — is set out in the Pulse white paper Stone Age to Space Age.
The Ingestion Engine
Two streams in — public-market data automatically, your own data privately — both run the same validated pipeline inside your encrypted environment, then surface in the platform, your own AI, and the agent modules.
| Input | Stream |
|---|---|
| Public market | 17 exchanges · filings · drill results — automatic |
| Your own data | Archives · technical reports · maps — private |
Your dedicated, encrypted environment: Ingest & extract → AuthentiQ™ validate → Structure & connect → Pulse platform · Your own AI via MCP · Agents & modules
What It Looks Like on the Platform
Example data — illustrative. The screenshots below use a randomly selected, publicly listed company — not the client described above — purely to show how digitised drill and resource data surfaces in the Pulse platform.
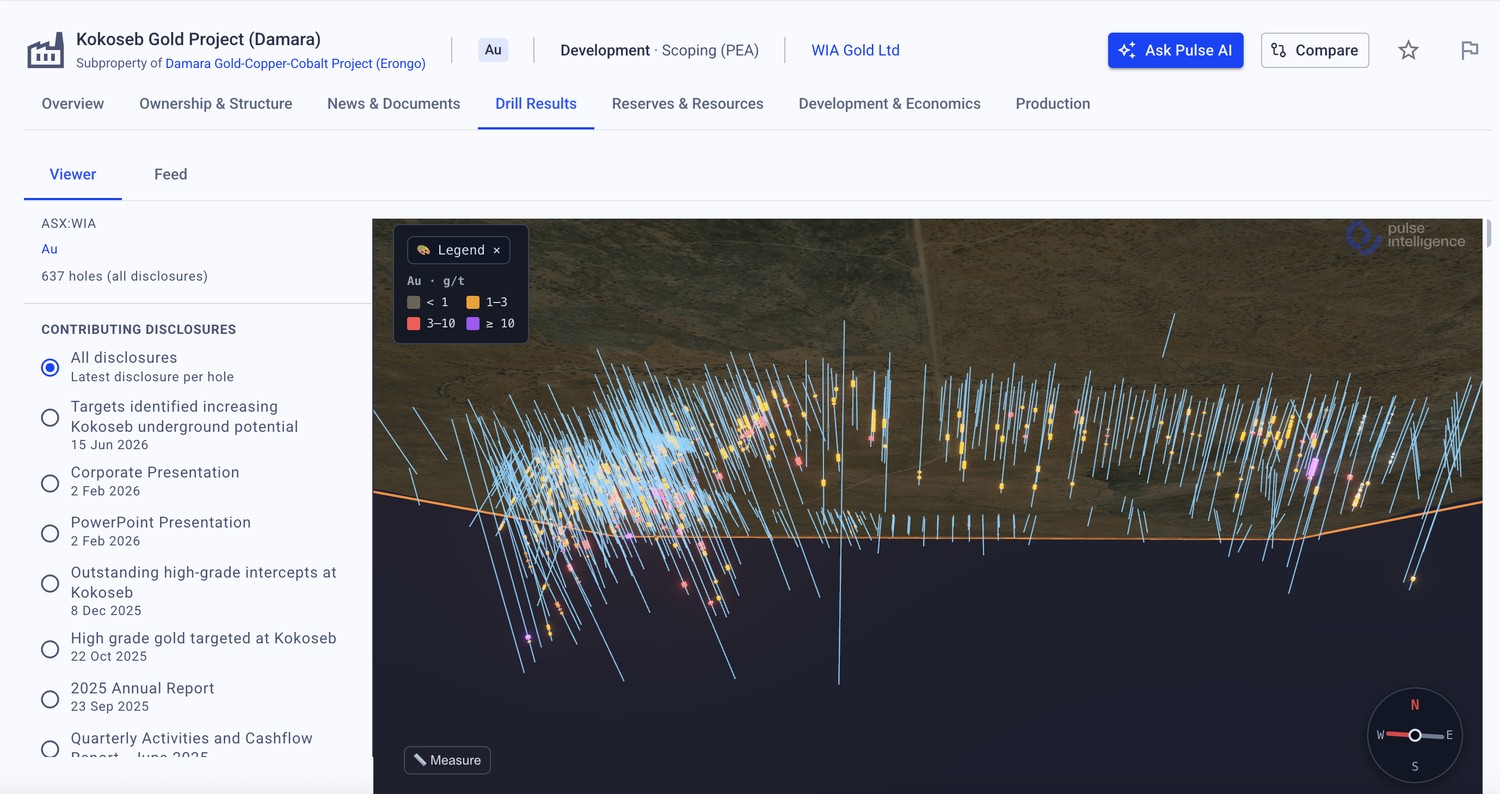
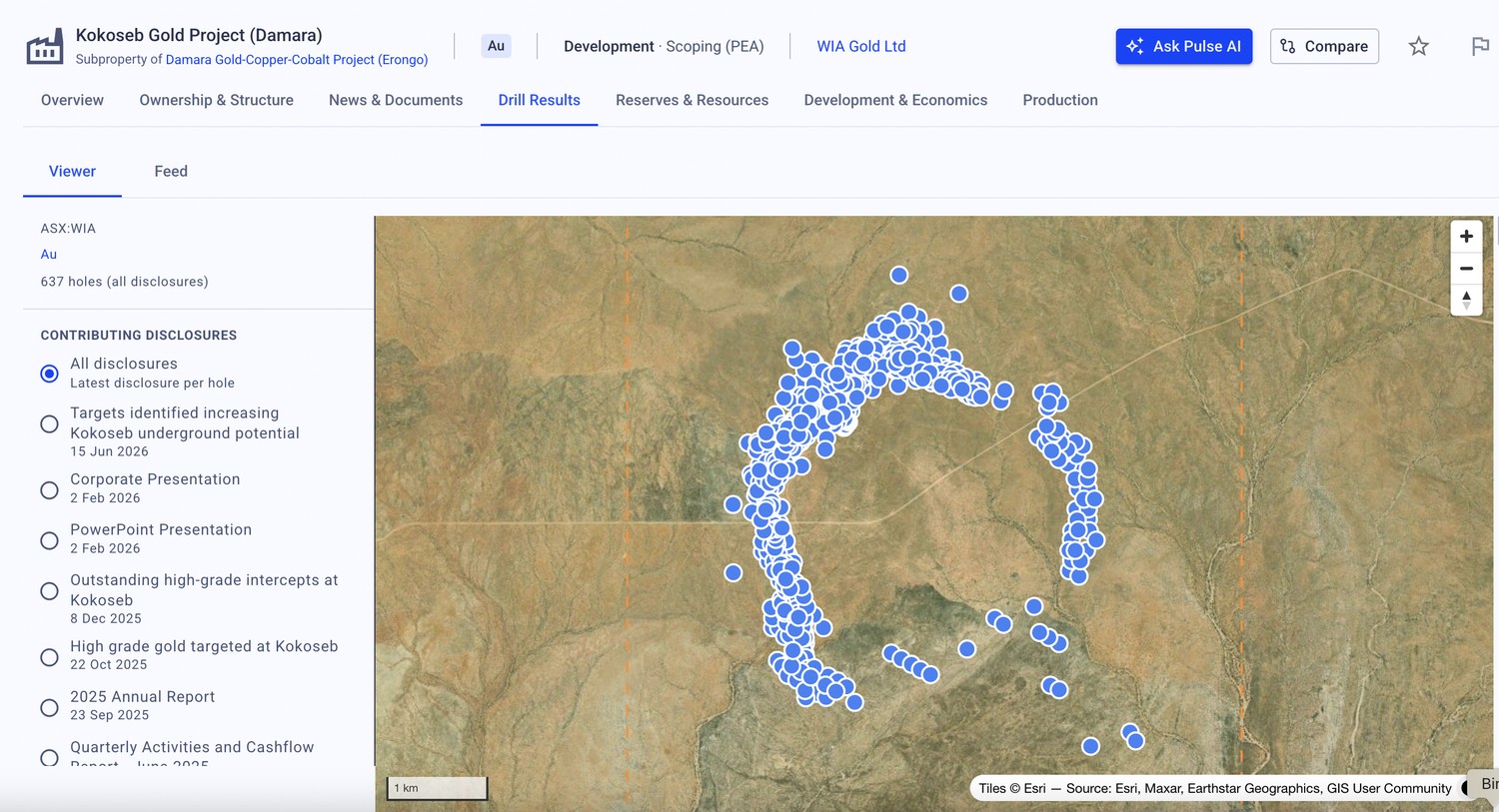
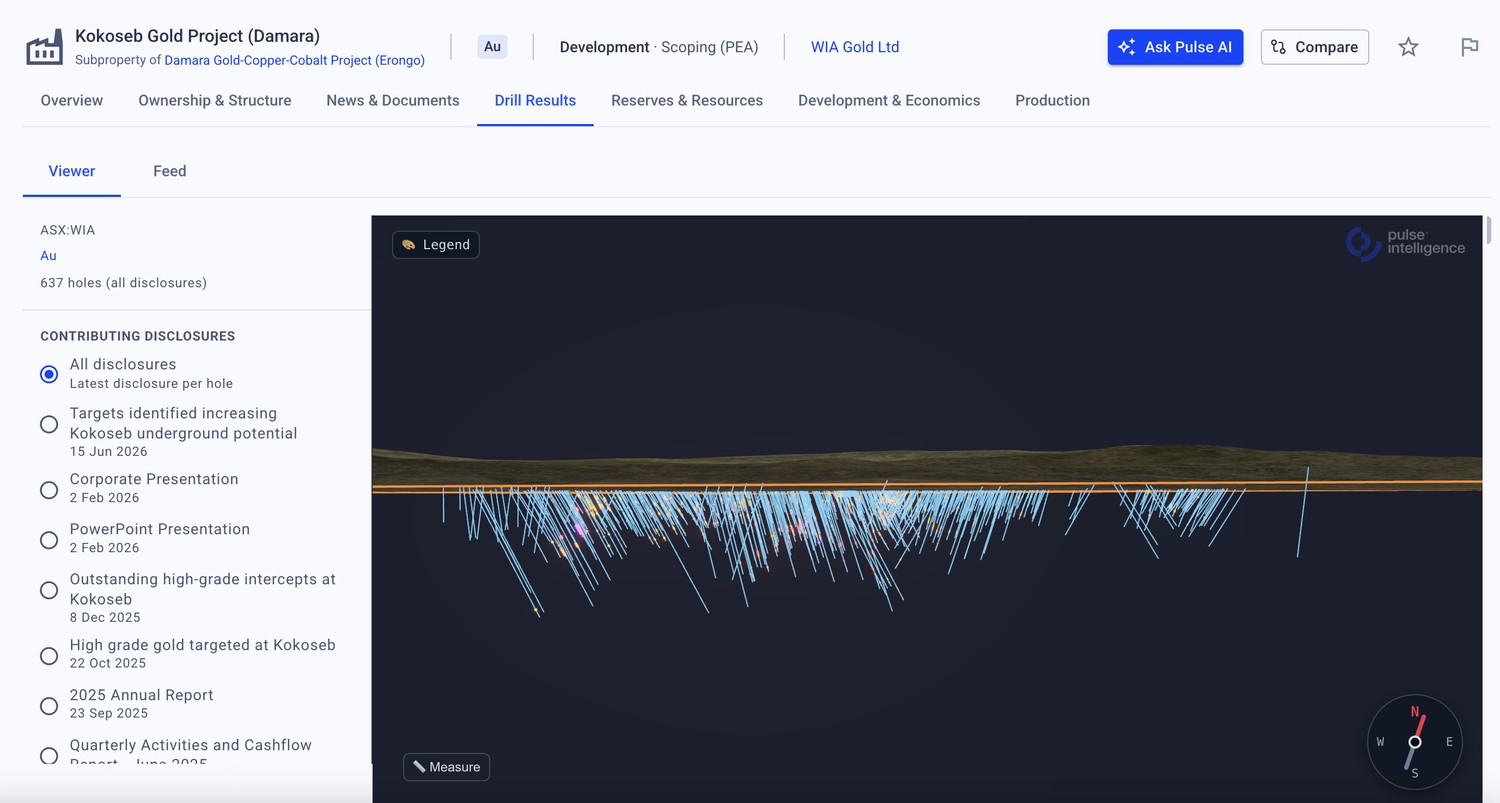
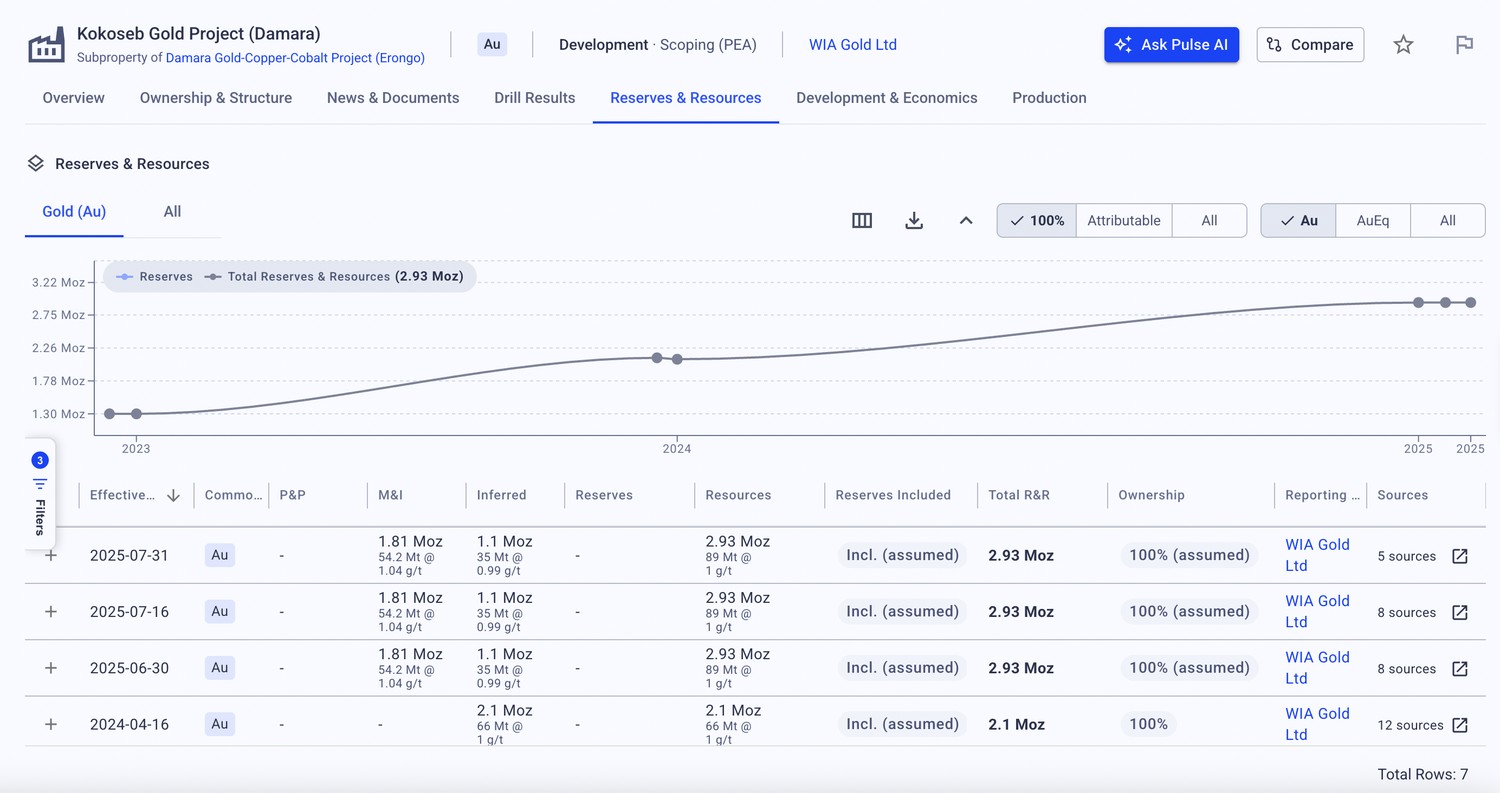
Less searching. More strategising.™
Where does your team's data infrastructure sit today?
Answer 10 questions. Get a private diagnostic on your AI readiness — in minutes.
Sitting on a legacy or multilingual archive? See what mining-grade extraction actually looks like.
See the platform running on real mining data. Book a demo to see what this looks like for your team.