Introducing our first Pulse Intelligence Partner vs. Claude performance benchmark.
We asked the same question in one single Claude session — to ensure consistency:
Name every lithium company in the US and Canada, from grassroots exploration through to definitive feasibility. Pin each one to its exact stage.
One method was our platform, connected via Claude MCP. The other was a general AI model — Claude Opus 4.8 — answering from memory, with no live mining data underneath it.

Pulse returned 283 companies. Every one tagged to its stage, every stage traceable to the filing it came from. In about five seconds.
The model named 38. Roughly one in seven. And several of those were mis-staged or already in construction, which puts them outside the question entirely.
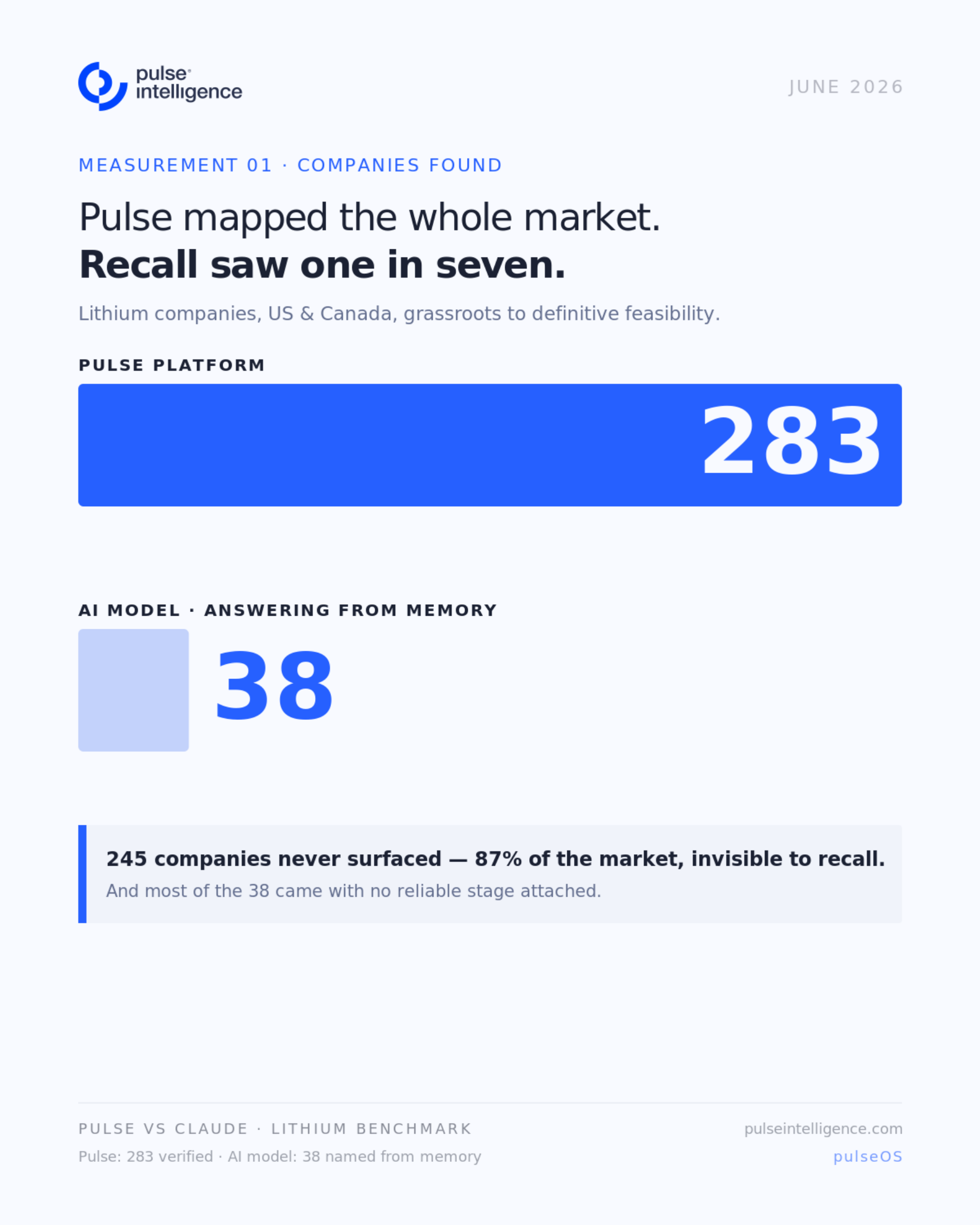
The 245 it never surfaced are not obscure. They are the junior explorers and single-asset developers that make up most of the lithium market in North America, and most of the movement in it.

This is the gap people underestimate. A capable model is not the same thing as a complete, auditable data foundation. Speed was never the hard part. Coverage you can stand behind is.

Now imagine adding actual complexity — 10 technical metrics, permitting status, leadership track record. It is simply not possible to achieve with a generic LLM if your definition of success is accuracy and data you can actually use without checking everything.
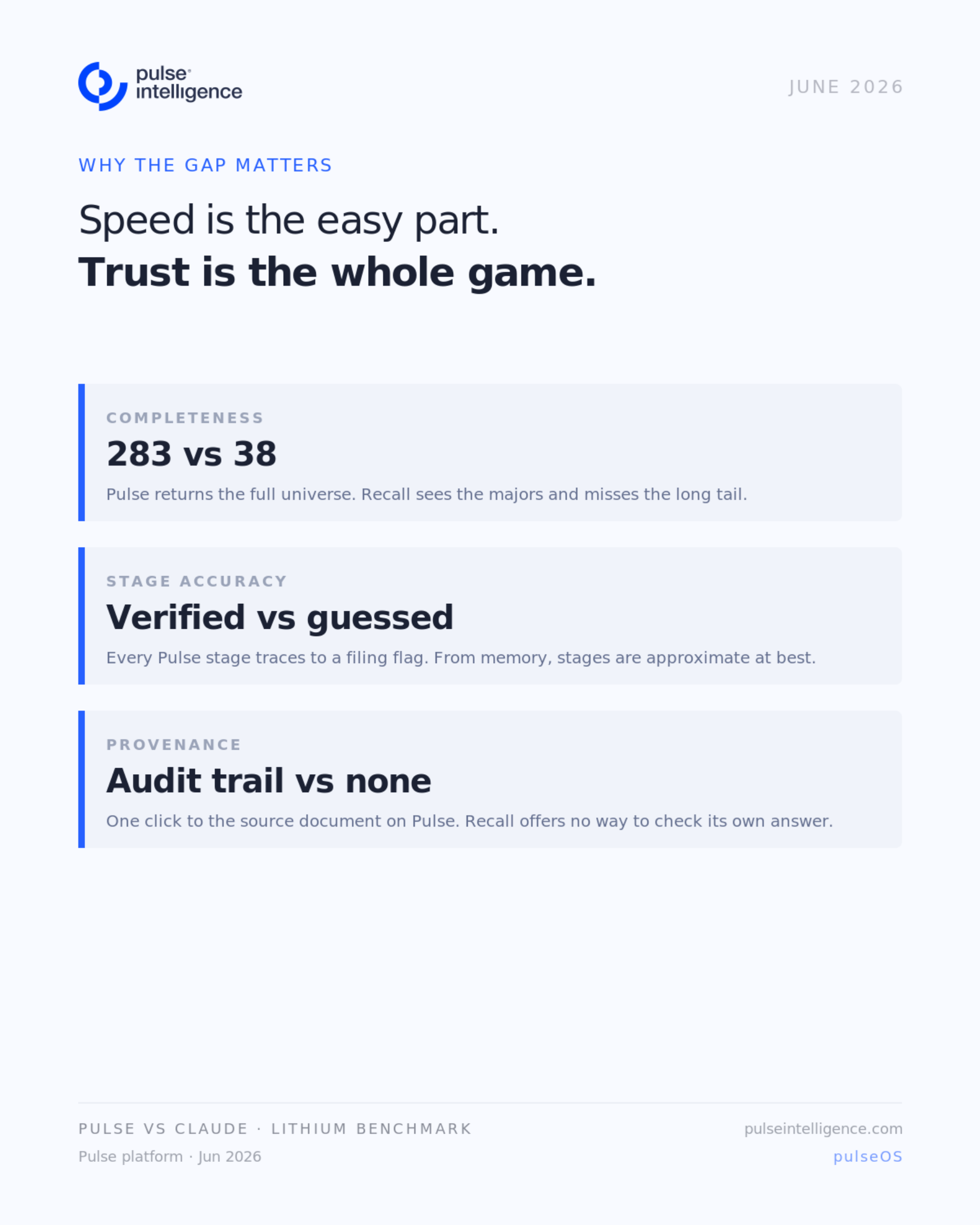
One honest qualifier: the model was answering cold, from training data, with no tools attached. That is exactly how most people are using AI to screen mining markets right now.
If your screening still depends on what a model can recall, there is a chance you are working from about 13% of the market.

Perhaps worth some reflection.
Less searching. More strategising.™
Where does your team's data infrastructure sit today?
Answer 10 questions. Get a private diagnostic on your AI readiness — in minutes.
Less Searching. More Strategising.™
See the platform running on real mining data. Book a demo to see what this looks like for your team.